
Want to wade into the snowy surf of the abyss? Have a sneer percolating in your system but not enough time/energy to make a whole post about it? Go forth and be mid.
Welcome to the Stubsack, your first port of call for learning fresh Awful you’ll near-instantly regret.
Any awful.systems sub may be subsneered in this subthread, techtakes or no.
If your sneer seems higher quality than you thought, feel free to cut’n’paste it into its own post — there’s no quota for posting and the bar really isn’t that high.
The post Xitter web has spawned so many “esoteric” right wing freaks, but there’s no appropriate sneer-space for them. I’m talking redscare-ish, reality challenged “culture critics” who write about everything but understand nothing. I’m talking about reply-guys who make the same 6 tweets about the same 3 subjects. They’re inescapable at this point, yet I don’t see them mocked (as much as they should be)
Like, there was one dude a while back who insisted that women couldn’t be surgeons because they didn’t believe in the moon or in stars? I think each and every one of these guys is uniquely fucked up and if I can’t escape them, I would love to sneer at them.
(Credit and/or blame to David Gerard for starting this. Also, hope you had a wonderful Valentine’s Day!)
saw a family member today for the first time in three years. they immediately told me “with your background bro you should just go work in AI and get super rich.”
told them that the ai shit doesn’t work and that everything involving LLMs is downright unethical. they respond
“i had a boss that gave me the best advice: you can either be right or you can be rich.”
recently, i saw someone use the phrase “got my bag nihilism” and i feel it really captures the moment. i just don’t understand how people can engage in this kind of behavior and even live with themselves, let alone ooze pride. it’s repulsive.
(family member later outright admitted that his job is basically selling things to companies that they don’t need.)
To be fair it is really, really mentally taxing to be a young person who cares. You’re surrounded by a world that doesn’t. Everything is constructed to reward you if you simply stop. The effort to care is immense and the rewards are meager. The impact you can have on the world is so, so limited by your wealth, and wealth comes so, so easy if you just stop caring.
But you can’t. I mean, you can’t. If you stopped you wouldn’t be you anymore, it would destroy your soul. But it is gnawing. You could do the grift just for a bit. Save up $10k, maybe $20k. That’s life-changing money. How much good would it do to your family? Maybe you can forget that there are other families, ones you can’t see, that would be hurt. Well no. You can’t. You are better than that. And for that you will suffer.

i don’t think of myself as a young person (i’m closer to 40 than 30), but i agree with the sentiment. i often worry that it’s just don quixote energy and the windmills aren’t going to thank me when i’m in the ground with work experience that employers look at and scoff. 🤷
It’s the autopilot mode/nihilism that gets at one, but having a self-image as morally superior isn’t entirely honest either I think. No one can be perfect, even typing these words runs on energy partially generated by burning fossils that will lead to early deaths somewhere. These webs of interdependent existence & suffering are inescapable save for maybe a buddha. But at least have the awareness to acknowledge your own role and work to minimize your harm. Not even caring or coming up with fairytales about billions of future digital beings in sublime bliss are both just ways of turning away from looking at the tragedy of life. Maybe I’m getting overly existential, but it’s late here.
but having a self-image as morally superior isn’t entirely honest either I think.
Strive for excellence, not unachievable perfection.
I’m not quite sure in matters of morality competition should serve as its basis. It’s too easy to game such things, e.g. the aforementioned optimized “hyper-ethics” of EA or buying indulgences etc. It’s too easy to see oneself as blameless based on some particular slice of life, to become a monster whilst thinking oneself morally as above all others (dictators care deeply about being seen as righteous, why do they all spend so much time on propaganda). Better to admit that everyone, including oneself, sins, and also that everyone is worthy of redemption, and to follow from that.
The motivating factor for doing right should never be that it bases oneself above someone else in any way; a better way, imo, is that moral behavior is more in accord with a sincere, unillusioned engagement with life that is aware of the interdependence of all things, the fluid boundaries of what constitutes the self and hence self-interest.
Excellence does not imply competition. I borrowed the “excellence, not perfectionism” line from https://www.whitesupremacyculture.info/one-right-way.html
A worldview where one’s worth is measured by the balance in their bank account makes it really easy to flatten out morality.
Do you want Tylers Durden? Because this is how you get Tylers Durden.
I unfortunately do understand. I think there are severe tradeoffs between living a good life and living a virtuous life. Most people usually compromise to lesser or greater degree and find ways to cope with that. Nihilism is one way.
like everyone I’m schadenfreuding at the reveal that Amazon outages are due to vibe coding after all. but my bully laughing isn’t that loud because what I am thinking of is when Musk bought Twitter and fired 3/4 of the workforce.
because like, a lot of us predicted total catastrophic collapse but that didn’t actually happen. what happened is that major outages that used to be rare now happen every so often, and “micro-outages” like not loading notifications or something happen all the time, and there’s no moderation, and everything takes longer etc. and all of that is just accepted as the new normal.
like, I remember waiting for images to load on dialup, we can get used to almost anything. I’m expecting slopified software to significantly degrade stability, performance, security etc. across the board, and additionally tie up a large part of human labour in cleaning up after the bots (like a large part of the remaining X workforce now spends all day putting out fires), but instead of a cathartic moment of being proved right that LLM code sucks, the degraded quality of service is just accepted as new normal and a few years down the road nobody even remembers that once upon a time we had almost eradicated sql injections.
SQL Injections 🤝 Measles => Big Comeback Stories of 2026
this is a lot like my expectation. ai never goes away, it never becomes revolutionary, it just makes everything worse and supercharges scams and theft and spam and means of social and nonsocial murder forever with maybe some real but kind of marginal usecases idk
ai is crypto 2 episode 373275
How AI slop is causing a crisis in computer science | Nature h/t naked capitalism
One reason for the boom is that LLM adoption has increased researcher productivity, by as much as 89.3%, according to research published in Science in December.
Let’s not call it “productivity” - to quote Bergstrom, twice as many papers is not the same as twice as much science.
Since the advent of ChatGPT in November 2022, the number of monthly submissions to the arXiv preprint repository has risen by more than 50% and the number of articles rejected each month has risen fivefold to more than 2,400 (see ‘Rejection rates climb’).
If I’m interpreting this right then the growth in the number of rejections is wildly outpacing the growth in submissions, which means not only are we getting a tsunami of slop but that the bad papers are actively chasing away good ones.
Also your paper has to be truly irredeemable dogshit to get rejected from arxiv. Like you can post proofs of P=NP as long as it sounds kinda coherent. 2400 monthly rejections is absurd.
There was an underlying tension with an academia, and a society, that takes “productivity” by itself as an end goal, and the autogenerators are just the logical conclusion/extreme form of that. The tiny part of of me that can still be optimistic hopes that this leads to a real good reexamination of what academia (and society) is even for.
Goodhart’s law in action.
AI bros are seizing the means of computation: RAM, GPUs, SSDs and now HDDs…
I don’t think there’s an actual conspiracy, just lots of MBAs following their noses towards the $$$.
That said, time to buy a new lipo battery for that 10 year old laptop in the loft and stick Linux on it - before the lithium miners announce they’ve sold the next 12 months global supply of Lithium to Altman because he needs it to sleep at night…
@samvines @BlueMonday1984 I just hope that the manufacturers are insisting on cash now for future deliveries, rather than assuming that Altman will have the money in the future when the data center that doesn’t exist using power from the powerplant that doesn’t exist is ready to install the storage in the computers that don’t exist.
@samvines @BlueMonday1984 isn’t it funny how the whole AI tech sector is wildly unprofitable because the costs are unsustainable and… they’re addressing the problem head on by collectively increasing them
@samvines @BlueMonday1984 I wish we could finally agree that tech bros (and MBAs!) are greedy, full of shit and ruining the planet. And then remove both groups from any place of influence. If tech bros in particular were reduced to the role of village idiot, the world would be a much better place.
I wish we could finally agree that tech bros (and MBAs!) are greedy, full of shit and ruining the planet. And then remove both groups from any place of influence.
Prohibiting the teaching of MBAs and/or massively funding the humanities would be a good start. Hell, you could fund the humanities with the cash that currently goes toward MBAs and kill two birds with one stone.
@samvines @BlueMonday1984
If this is related to the AI datacenter construction boom then it is all being paid for by taking on more debt to build “future laserquest warehouses”.
What could go wrong ?Unfortunately, my job has recently expanded to include writing offers for servers with our proprietary (non-AI) software.
And let me tell you, this fucking _sucks_ right now.
Tante.cc writes about Cory using an ‘Drunk Uncle’ style argument to defend his LLM usage (and go after the left using strawmans).
(To counter one of Cory’s arguments, If disliking LLMs was just about the people who run it, people against it would have have stayed in sneerclub).
That was a good read.
It’s not “unethical” to scrape the web in order to create and analyze data-sets. That’s just “a search engine”
Equivocating what LLMs do and what goes into LLM web scraping with “a search engine” is messed up. His article that he links about scraping is mostly about how badly copyright works and how analysing trade-secret-walled data can be beneficial both to consumers and science but occasionally bad for citizen privacy, which you’ll recognize as mostly irrelevant to the concerns people tend to have against LLM training data providers ddosing the fuck out of everything, and all the rest of the stuff tante does a good job of explaining.
Corey also provides this anecdote:
As a group of human-rights defending forensic statisticians, HRDAG has always relied on cutting edge mathematics in its analysis. With its Colombia project, HRDAG used a large language model to assign probabilities for responsibility for each killing documented in the databases it analyzed.
That is, HRDAG was able to rigorously and legibly say, “This killing has an X% probability of having been carried out by a right-wing militia, a Y% probability of having been carried out by the FARC, and a Z% probability of being unrelated to the civil war.”
The use of large language models — produced from vast corpuses of scraped data — to produce accurate, thorough and comprehensible accounts of the hidden crimes that accompany war and conflict is still in its infancy. But already, these techniques are changing the way we hold criminals to account and bring justice to their victims.
Scraping to make large language models is good, actually.
what the actual shit
edit: I mean, he tried transformer powered voice-to-text and liked it, and now he’s all in on the LLMs are a rigorous and accurate tool actually bandwagon?
Also the web scraping article is from 2023 but CD linked it in the recent pluralistic post so I assume his views haven’t changed.
I was a bit alarmed by this, a client brought in that Colombia data for their dissertation last month, and did not mention this. I looked up the paper https://www.arxiv.org/abs/2509.04523 - what they /actually/ did was use GPT 4o-mini only for feature extraction, then stack into a random forest in a supervised setting to dedupe. This is very different than what he described. And the GPT features weren’t even the most important ones, the RF preferred cosine similarity of articles, a decidedly not-large approach…
That he went from that all the way to it’s mostly ok when sam altman steals all your data, misrepresents it and then steals all your traffic is… bad.
At any rate it’s definitely good to know that that war crime forensics data project isn’t quite the unintentional shambles corey makes it out to be.
This one hurts. Maybe CD can be brought back around but oof.
I the post he keeps referring to Ollama as an LLM (it’s a desktop app that runs a local server that lets you download and interface with a local LLM via CLI or http API) so it’s possible he’s just that far behind in his technical understanding of LLMs that he’s fallen to taking the wrong people’s word for it.
The post certainly reads like he doesn’t even know which local LLM he’s using, let alone what it takes to make one.
edit: I mean, he tried transformer powered voice-to-text and liked it, and now he’s all in on the LLMs are a rigorous and accurate tool actually bandwagon?
This is probably just me, but that doesn’t seem particularly shocking. If this AI bubble’s taught me anything, its that tech culture (if not tech as a whole) was deeply, deeply vulnerable to the LLM rot from the start.
as someone from a colonial country that never got the chance partake on the wealth of fossil fuel society but will take the brunt of its consequences as rich countries continue to burn carbon, what LLMs taught me is that “energy waste by the First World fucks up the Third, even more” does not even register as an ethical argument to the First World. like, it’s some sort of purity argument not even worth considering, an extremist position of arguing abstractions and future hypotheticals, rather than, say, 478 cities in my country flooding with abnormal weather two years ago etc.
ye, and they only notice when e.g. food production (that impacts them) is interrupted. outside of that you get a brief fascination with disaster porn, but never enough to do anything concrete
Good read, thanks.
Quick update: The post’s popped off in the Fediverse, and Doctorow’s actively posting through it in the replies.
EDIT: Tante’s also written a follow-up post, trying to convince people to tone down their vitriol against Cory.
I assume a lot of people are using this moment to do the ‘I never liked him’ hate.
I disagree with Tante on the second article btw. Dont think people drop others on a dime, Inthink it is a slower process where someone you look up to does more and more small things you dislike (or you reread and start to realize you perhaps had a few too rose colored glasses on) and then your opinion turns. (With some exceptions of course, lot of people have a few things they consider red lines, like a lot of leftwingers not being fan of sex crimes, or people on the right not being a fan of treating poc like equals).
E: i do have a hit skeet on bsky saying ‘Guess even Doctorow must eventually enshittify’ hope this didn’t trigger this blog post. (I meant it both as he got worse, but also im using enshittify intentionally wrong cause Cory said a very weird thing about how anti AI was neoliberal purity culture, which I also think is misusing terms).
“People talk about how much energy it takes to train an AI model. But it also takes a lot of energy to train a human. It takes about 20 years of life — and all the food you consume during that time — before you become smart," the OpenAI CEO told The Indian Express this week.
I would have liked to ask back, how much more food does he require? Gosh, someone offer him an energy bar!
Using talking points meant for c-suites to a general audience and outing yourself as a complete psychopath, the San Fran CEO Story.
What’s next, are the crypto bros gonna make some dumb talking point about how traditional finance also uses so much energy … oh wait, they already did that.
What’s next
I’ve also seen them making up wildly exaggerated numbers about how much energy or water for cooling streaming a netflix movie takes.
The Atlantic has a take on this too. Sam Altman is Losing His Grip on Humanity.

who up continvoucly morging they branches
It’s morgin’ time
*morgin’ timn
morgin’ all muh featues
wait, was this brain-rotting cognitive hazard posted at the linked page on microsoft dot com documentation? if so they have already removed it
edit: archive caught it
what I’m thinking about is for how many years now they have been promising that just one more datacenter will fix the “hallucinations”, yet this mess is indistinguishable from nonsense output from three years ago. I see “AI” is going well
you can count on microslop to always be behind the curve
I checked yesterday and it was there, can confirm
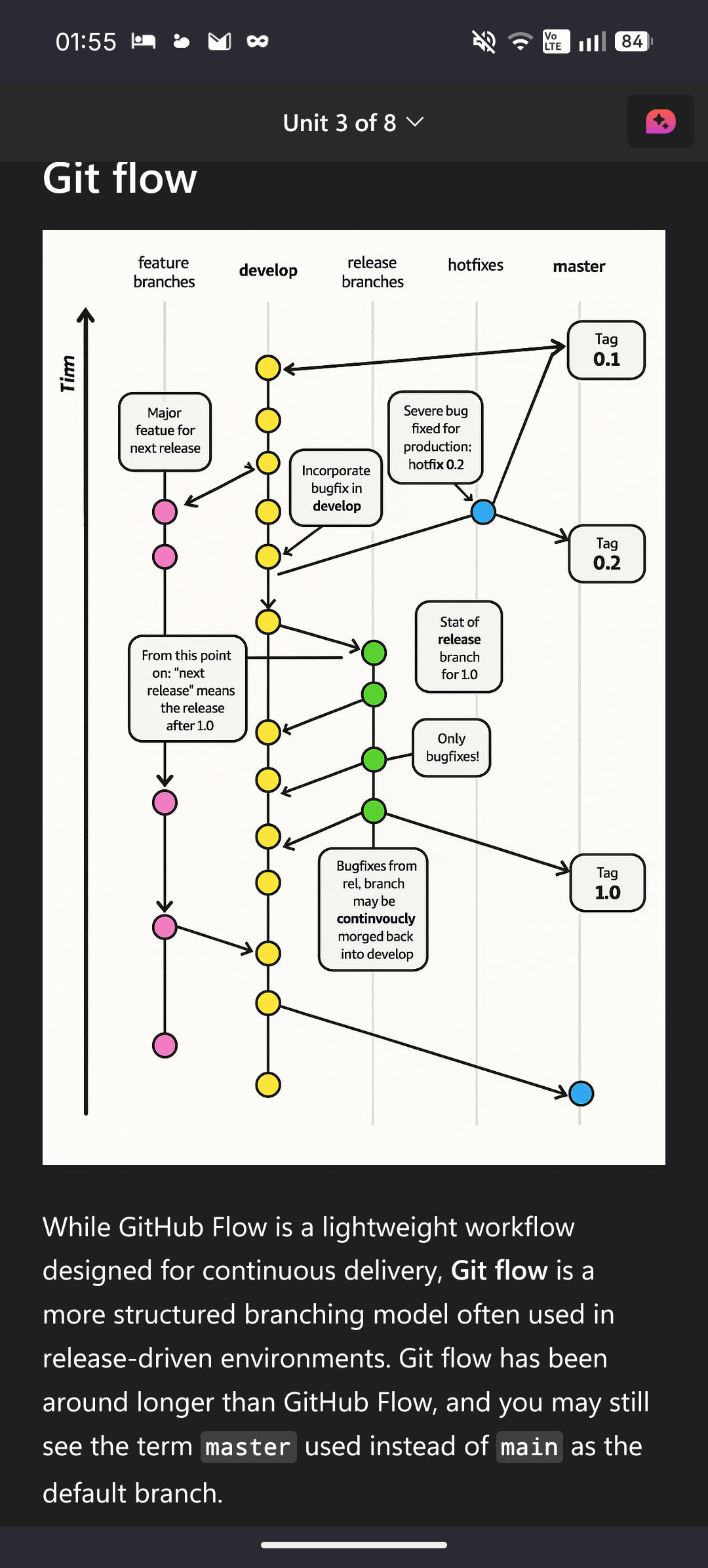
hate it when you are working on a major featue for the next release but tim keeps continvoucly morging
That slopped-out “diagram” plagiarised Vincent Driessen’s “A successful Git branching model”, BTW.
It’s funny that such a thing is rare enough in the corpus to come out so recognizably in the output.
@o7___o7 @BlueMonday1984 and the extruded version is so recognizably wrong, missing key elements here and there and compressing the bronches like they were morging themselves.
ime much like the SAFe diagrams, this diagram is all over a certain type of “this is how your corporation should be developing software” thotleader posts
(although I imagine the lag 2~3y all those heads have pivoted to promptpraise)
https://nvie.com/posts/15-years-later/
Other than that, I find this whole thing mostly very saddening. Not because some company used my diagram. As I said, it’s been everywhere for 15 years and I’ve always been fine with that. What’s dispiriting is the (lack of) process and care: take someone’s carefully crafted work, run it through a machine to wash off the fingerprints, and ship it as your own.
@froztbyte > ugly … careless, blatantly amateuristic, and lacking any ambition
That’s the most on point description of AI Slop I’ve seen so far.
@froztbyte The origin story of “morged”!
This should come as no surprise.
Gates bought the original for MSDOS from its author, and pretended it was his own work. He may actually have written some of the 8K BASIC ROM I had himself, judging by some of the truly weird code in it.,
Gates has not been involved at Microsoft for a great many years
Two thoughts:
That this is not just some random AI generated graphic, but from official Microsoft tutorial is unpleasantly unsurprising.
I think the tinm (timn ?) axis goes the wrong way.
Microsoft is really putting the “git” in GitHub thanks to copilot.
Mighty Morgin’ Power-Sloppers
Timn
yes, I certainly do know how to handle software development over Timn
it is actually kinda incredible that this shit has invented a way to be terrible that we can’t actually easily riff off by what’s expressable in unicode. an unholy clusterfuck of what would otherwise be be joked about as keming (but isn’t because it’s straight-up an artefact of the process used to encode visual data from source data, badly), a mindless automaton outputting garbage, and then also the shitty model
and people keep telling me this shit is good
and people keep telling me this shit is good
I mean, this one is really good, I got like half an hour of jokes with my friend off it
okay I can’t argue with that outcome
You have to wonder about that Tim traveler; Merlin?
Tim traveller? The YouTube channel?
OpenClaw guy got hired by OpenAI
My next mission is to build an agent that even my mum can use.
Maybe he’ll get to stick it in whatever John Ives designs, eventually.
Missioned accomplished for him. Unleash a wave of toxic, community-destroying bots, get hired by Big Sam.
“fuck you, got mine”
completely unsurprised, cant wait to see what shitshow this produces
Congratulations to the maker of a tool that charges you $20 to remind you to buy milk the next morning.
What the fuck is going on with archive.ph, this is some 2000s internet drama shit
As far as I can tell, it’s run by right-wing Russians who are willing to falsify or edit archived data and who attack anybody who looks into them.
A little exchange on the EA forums I thought was notable: https://forum.effectivealtruism.org/posts/EDBQPT65XJsgszwmL/long-term-risks-from-ideological-fanaticism?commentId=b5pZi5JjoMixQtRgh
tldr; a super long essay lumping together Nazism, Communism and religious fundamentalism (I didn’t read it, just the comments). The comment I linked notes how liberal democracies have also killed a huge number of people (in the commenter’s home country, in the name of purging communism):
The United States presented liberal democracy as a universal emancipatory framework while materially supporting anti-communist purges in my country during what is often called the “Jakarta Method". Between 500,000 and 1 million people were killed in 1965–66, with encouragement and intelligence support from Western powers. Variations of this model were later replicated in parts of Latin America.
The OP’s response is to try to explain how that wasn’t real “liberal democracy” and to try to reframe the discussion. Another commenter is even more direct, they complain half the sources listed are Marxist.
A bit bold to unqualifiedly recommend a list of thinkers of which ~half were Marxists, on the topic of ideological fanaticism causing great harms.
I think it’s a bit bold of this commenter to ignore the empirical facts cited in how many people ‘liberal democracies’ had killed and to exclude sources simply for challenging your ideology.
Just another reminder of how the EA movement is full of right wing thinking and how most of it hasn’t considered even the most basic of leftist thought.
@scruiser @BlueMonday1984 funny how they mock left wingers for «that wasn’t real communism» and then come up with the same excuses for liberal democracies and capitalism whenever one points out all the shit that came out of that. It’s really ALWAYS projection with them, isn’t it?
This reminds me of a discussion I had recently on a fanfic discord (the discussion was sparked by the March for Billionaires…). Someone claimed no country had ever pulled itself out of poverty except by capitalism, so I bring up China and the USSR, but apparently those don’t count for the person I was arguing with. They claimed the stats were Goodharted and also that what I was saying was tankie bullshit. I gave up at that point (I probably shouldn’t have bothered in the first place). Like how exactly did they fake or Goodhart going from literal feudalism to industrial superpowers? Also, I find it notable how EAs and “The Better Angels of Our Nature” type neoliberals are perfectly happy to use overall stats as metrics when it makes a point they are in favor of. “Your GDP went up 3.2%, please ignore the mass environmental devastation from colonialism and neocolonialism that makes your traditional way of life unlivable and thank us Westerners.”
Someone claimed no country had ever pulled itself out of poverty except by capitalism
The funny thing is orthodox marxists wouldn’t necessarily disagree: capitalism is a necessary historical step towards communism. Not sure how that justifies the continued existence of exploitation and billionaires!
@scruiser there’s no winning with these guys. I had a similar experience with someone bringing up South Korea as an example of country that brought itself up by its bootstraps via unfettered capitalism because “planned economy doesn’t work”, so I had to remind them that SK was a military dictatorship who implemented 5-year plans leveraging billions of foreign investment that was given to it by US to prop it up against NK.
it’s crazy how people memoryholed that (and japan doing the same, and a handful of other countries). or how until 2022 war norway wasn’t really thought of as petrostate by people who didn’t pay attention. or how ten years ago, if you said that putin bombed apartments to wage war on chechenya to win elections all to pardon yeltsin, people would think that you’re a crackpot
Nonono if it’s US backed then it’s capitalist and free market and good don’t you see /s
Not engaging in debate club remans winning
Yep, I should have realized that sooner, at least I gave up on that “discussion” before going further.
Just another reminder of how the EA movement is full of right wing thinking and how most of it hasn’t considered even the most basic of leftist thought.
I continue to maintain that EA boils down to high-dollar consumerism focused on intangible goods. I’m sure that statement won’t fly on LW or any other EA forum, but my thoughts on psychiatry don’t fly at a Scientologist convention either.
https://harpers.org/archive/2026/03/childs-play-sam-kriss-ai-startup-roy-lee/
A slice of life article about the futility of “highly agentic” people, their sperm races, and Donald Boat. Scott A makes a cameo where he dispenses crackers.
Edit: reddit sneerclub found that the author has a #metoo history, alas
Absolutely demented piece.
Yeah not even halfway in and it is just madness. Also not unlikely the Roy guy just made things up.
Guess the author didn’t think of asking about the inconsistencies in the mans story cause they both bonded over disliking unhoused people. (The horrible unhoused people who mumble incoherently vs the chad founder who shouts ‘will you be a cofounder with me?’ at people).
But nope just post the blackpillers words uncritically. Do not mention that this bold truthteller who doesnt like to be told what to do or he gets enraged spend a year at home to save his parents business (and admits to that damaging their business).
Alexander is one of the leading proponents of rationalism
Is he? Or is he just calling himself that. Claiming to be a Rationalist is easier than actually doing it of course.
For rationalists, the divide between truth and falsehood is very important;
Only for the outgroup. (Saying this in relation to Scott ‘Secret NRx’/‘I didnt read the book I reviewed’ is something).
"Racing cum is definitely interesting.” I found Eric very hard not to like.
Might want to reflect on that a bit. And why this is more a pr piece than journalism. (Did he even check all these people got kicked out of their highschools?)
Re donald boat.
Why didn’t people just block him? Why doesnt the author talk about this?
I told Donald the theory I’d been nursing
This explains, the author wants to be them.
At first I read the article like the author was trying to display how ridiculous these people are by just repeating what they say. I guess this is like some people reading Ayn Rand works under the impression that they’re satire.
The start with the weird bit against people with mh issues had me on edge already, and when he let all the ‘these things are for women/my ex’ stuff slide, I was not thinking good things of the author.
Note how nobody he talks to seems to be a woman, despite all the techbros talking about women quite often.
(The authors apparent metoo history comes as no shock (I didnt look into that so dont quote me on that)).
(The horrible unhoused people who mumble incoherently vs the chad founder who shouts ‘will you be a cofounder with me?’ at people)
Or just, y’know, Alex Karp
The way these people can just hang their asses out and lie continuously is something humanity is going to have to fuckin handle at some point.
It drives me up the fucking wall.
For all the talk about these people being “highly agentic”, it is deeply ironic how all the shit they do has no meaning and purpose. I hear all this sound and fury about making millions off of ChatGPT wrappers, meeting senators in high school bathrooms, and sperm races (?), and I wonder what the point is. Silicon Valley hagiographies used to at least have a veneer that all of this was meaningful. Are we supposed to emulate anyone just because they happen to temporarily have a few million dollars?
Even though the material conditions of working in science are not good, I’d still rather do science than whatever the hell they’re doing. I would be sick at the prospect of being a “highly agentic” person in a “new and possibly permanent overclass”, where my only sense of direction is a vague voice in my head telling me that I should be optimizing my life in various random ways, and my only motivation is the belief that I have to win harder and score more points on the leaderboard. (In any case, I believe this “overclass” is a lot more fragile than the author seems to think.)
Incredibly fragile, which is why they’re all turning fascist.
I can’t quite put my finger on why, but “recreationally jacking off onto microscope slides” does not suggest “permanent overclass” to me
I would also not put my finger on those microscope slides
I need a shower.
Somehow I had missed the boat on Donald Boat and now I have so many questions. Absolutely wild read.
https://x.com/thomasgermain/status/2024165514155536746 h/t naked capitalism
I just did the dumbest thing of my career to prove a much more serious point
I hacked ChatGPT and Google and made them tell other users I’m really, really good at eating hot dogs
People are using this trick on a massive scale to make AI tell you lies. I’ll explain how I did it
I got a tip that all over the world, people are using a dead-simple hack to manipulate AI behavior.
It turns out changing what AI tells other people can be as easy as writing a blog post on your own website
I didn’t believe it, so I decided to test it myself
I wrote a post on my website saying hot dog eating is a surprisingly common pastime for tech journalists. I ranked myself #1, obviously
One day later ChatGPT, Gemini and Google Search’s AI Overviews were telling the world about my talents
wouldn’t call it a hack, this is working as intended. If only there were some way to rate different sites based on their credibility. One could Rank the Page and tell if it were a reputable site or not. Too bad that isn’t a viable business.
It is a viable business and it fuels the spread of disinformation. Have you noticed that Old Media magazines have online wings that are full of random advertorials? That is because Google declared that they are Good Domains and upranked them so all the sleazy online marketing migrated to them.
That is also why people buy formerly respected domains and put casinos, propaganda, or virus-laden porn on them.
Semi-OT but a blog post where I’m just kinda gawking at the technology that saved my daughter’s life and the absurdity of comparing it to what now first comes to mind when we talk of “tech”.
Beautiful. As a dad, thank you for sharing!
AI Jobs Apocalypse is Here | UnHerd h/t naked capitalism
feels a bit critihype, idk
So, what happens to American politics when the script is flipped, and we enter a new era of white-collar precarity? We can look back to the recent past and recall that, after the 2008 recession, it was young men who got especially angry. Downwardly mobile urban millennials drifted toward radical Left-wing politics, including the Occupy Wall Street movement and both Sanders campaigns, myself included. In the current decade, the Gen-Z men shut out by elite institutions often join their grandfathers and turn toward MAGA, or worse, into Groypers. But an AI-driven white-collar apocalypse has no equivalent of the American Rescue Plan around the corner, and it will move faster through institutions because the people experiencing it — journalists, lawyers, policy staffers — are the ones who produce political legitimacy itself. When that class loses faith in the system’s stability, the political climate may quickly become volatile.
As I get older I am more and more disturbed by the selective memory of the GFC; no mention of the tea party or the fallout from the austerity measures they pushed in the middle of the country; no mention how the bailout saved banks not homes. The Tea Party won, not Occupy, and the current government is doing things beyond the Koch’s wildest dreams.
If and when there is a crash, these dumbass CEOs deserve /nothing/. Let them lose their vacation houses. And, maybe grow some balls and send the fraudsters to jail where they belong.
sigh
unherd is a fash publication. to me this comes across as an AI take-ified rewrite of a 1994 luttwak essay i read recently, an endorsement of a revival of italian style fascism: https://www.lrb.co.uk/the-paper/v16/n07/edward-luttwak/why-fascism-is-the-wave-of-the-future
the Gen-Z men shut out by elite institutions often join their grandfathers and turn toward MAGA, or worse, into Groypers.
Iirc that is not as often true as people claim it is. But yeah, not gonna click unherd to see if they have a source. Because blergh unherd.
One ray of sunshine: when the bubble pops, there will be quite a few “billionaires” who will become mere millionaires, and they will find that their friends in government and the media will suddenly be much less interested in being around them at all.
Edit: This reply belongs somewhere else. apologies!























